Why You Should Use Type Hints in Python
• Author: Peter Schmidbauer •
Table of Contents
Introduction
A note from Pyter the bird 🐦💬: This article is aimed mainly at data engineers, but also at all other beginner or even experienced Pythonistas who do not use type hints (yet). We do assume that you are at least comfortable using functions, though!
As you might know, Python is a dynamically typed language. This allows you to write code like this:
# <- insert code for long running data pipeline
return
=
=
…without having a compiler yell at you. Did you spot the error? run_data_pipeline returns a pd.Series (which is basically a column of the DataFrame), however, print_pipeline_results expects a pd.DataFrame as input! While it is obvious here in this small snippet, in real code problems like these are much harder to spot.
Python will happily try to execute your code, running all your data transformations, machine learning algorithms and other experiments. Once it has finally done all that work, it reaches your print_pipeline_results function and…1
Well, in this case we did not actually get a TypeError, but a KeyError:
File "/path/to/project/data_pipeline.py", line 4, in print_pipeline_results
print(df["result_column"])
~~^^^^^^^^^^^^^^^^^
File "/path/to/project/.venv/lib/python3.12/site-packages/pandas/core/series.py", line 1111, in __getitem__
return self._get_value(key)
^^^^^^^^^^^^^^^^^^^^
File "/path/to/project/.venv/lib/python3.12/site-packages/pandas/core/series.py", line 1227, in _get_value
loc = self.index.get_loc(label)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/path/to/project/.venv/lib/python3.12/site-packages/pandas/core/indexes/range.py", line 417, in get_loc
raise KeyError(key)
KeyError: 'result_column'
Nonetheless, such mistakes can throw you back hours or even days, if it happens at the last moment of your long-running batch job. And of course, it probably won’t happen just once. Since you will be continuously working on your pipeline, and everyone makes mistakes sometimes, it will eventually happen again, and again.
I will tell you a secret: Most of them could be avoided with just a few changes to how you code.
Type Issues Are Nasty Creatures
When you are only creating small, short-running analysis scripts, this is usually not a huge deal since you can spot such mistakes before they blow up. If your script finishes in a few seconds or less, then you can just try to execute it and see if it fails or not.
But if your script or batch job takes hours to complete, you probably run it overnight. You’ve got a nice data pipeline here, would be a shame if something happened to it at the very end right before it outputs the results!
Or maybe you work on services running continuously in production? Whether it is an API, a data pipeline or some microservice, who gets a call if things break on a Friday afternoon?
The Hidden Dangers of Abstraction
The more your project grows in complexity and size, the more such errors can be hidden behind layers of indirection and abstraction. Maybe your colleague implemented a function that usually works when passed a float, but was actually meant to be used with an int. When there’s no decimal places, it might work, but then your input changes and boom 🧨🔥, we end up like our poor guy in a lab coat in the image above.
A wrongly typed parameter can be passed around through multiple functions or classes, until it ends up somewhere where it shouldn’t and crashes the program. This makes spotting such errors just by reading your own code very difficult. You might have to dig through multiple layers of functions and classes to get to the source of the bug.
Testing does not solve everything
If the problem does not surface during unit tests, maybe because it only happens under specific conditions in the production environment, good luck finding the source of that bug. That is, if you even have a test for that part of the code. And even if your tests have 100% line coverage, they still might miss a situation where the same lines receive a wrong type. (To be clear, most projects do not have 100% test coverage, especially not in the data world.)
🐦 Chirp, chirp 🎶! I mean, ahem, can’t you just document what type you expect to receive in some comments or the function’s docstring?
Ah, thanks for the question, Pyter. You could, of course, always document exactly which types your function supports. However, there is no way to automatically check if your code is actually following the constraints in your comments (unless you use the old-school comment-based type hints, but those are type hints, and the only ones you could use pre Python 3.6). There’s no way to automatically check if you forgot to add a comment for some argument. And even if you add everything correctly, you may change parts of the function later and forget about updating the comment, which happens all the time. Your IDE also cannot read your free text comments and warn you about improper type use (at least not yet). But more on IDEs later.
Thankfully, Python nowadays has a built-in typing system using type hints that solve all these issues. The above functions with type hints look like this:
# code for long-running data pipeline
return
I will note right away that these type hints do not change anything about how your code acts when it is run. It will still crash if you pass a Series to the print function, just like before, but not because of the type hints and not because the function suddenly knows that you are passing an object with the wrong type. Instead, Python will go ahead and call your function with the Series, and, blissfully ignorant of the type hints, will throw exactly the same KeyError when trying to access a row with the index "result_column".
🐦 But… then so what, why is that better than the comments I suggested earlier?
I’ll get to it, Pyter. While yes, the type hints on your function are (mostly) ignored by the interpreter2, they are still far from being useless.
Benefits of using Type Hints
While it requires a bit more upfront work and knowledge, there’s a couple of big benefits to using type hints. Let’s explore them!
🛡️️ Your IDE can save you from mistakes 🛡️️
The probably most immediate and major benefit of using type hints is that IDEs like Pycharm or VS Codium are able to analyze them and tell you right away that something is wrong here even without running your code:
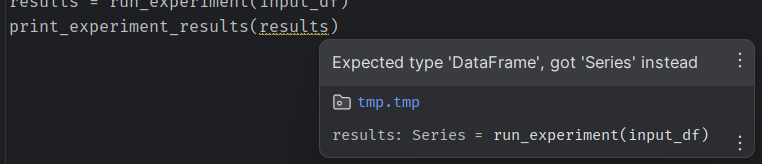
These checks are pretty good, and enough to save your ass in many cases, but the IDE’s type checkers are optimized for speed and low resource consumption so that they can continuously run in the background. They can catch simple issues without breaking a sweat, but they aren’t perfect in all cases.
External Type Checkers
If you want to benefit from the full support that static type checking can give you, you probably want to use automated tools that can read your whole code base and compile a list of every single typing issue that it finds. This is similar to a compiler giving you a list of compiler errors. In a statically typed language, you wouldn’t even be able to run any of your code if you try passing an object of the wrong type to a function that does not expect that type.
In Python, there is no compiler3, but to fill that hole, you can consult type checkers like pyright and mypy to tell you if your code is sound. These can eliminate a lot of issues before you start that long-running job, or before they end up in a production service.
🐦 Until you forget to run the type checker and still run into the same problem!
Good point! Whenever some program should run before you push your changes somewhere, and it relies on you not forgetting it, it’s a good idea to automate that task. I always add mypy to my continuous integration (CI) pipeline to enforce type checking in my repositories. Moreover, I like to use pre-commit to run the type checker on every change I commit. With these tools, I get immediate feedback and (almost) never end up with type problems.
We may explore these tools further in another blog post!
Less typing, more code 📈
So far, we only talked about how type hints, while more work up front, help you prevent mistakes. But did you know that type hints may actually speed up your development?
🐦 How is that possible if you have to do more… typing?
Code completion enters the stage!
Once you typed your functions and classes, your IDE knows exactly which of your variables has which type. Therefore, it can now tell you, for example, what the valid methods of this variable are, what type each method returns and what parameters the method takes.
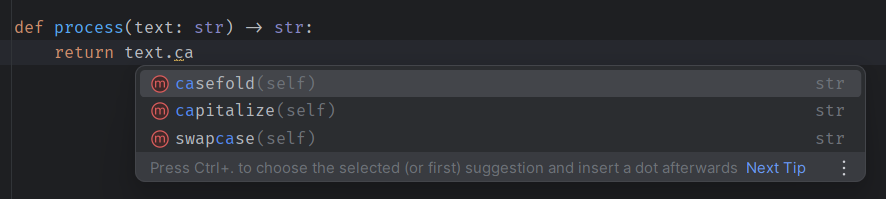
This is just not possible at such extent without type hints. Sure, if you create an object of a class directly, your IDE knows the type of the object you just created. But in reality, you often get the object from a function or method. Take pd.read_csv for example. If the maintainers of pandas hadn’t added a type hint to this function, your IDE would have no idea that it returns a DataFrame4.
You don’t have to type everything (at once)
Of course, due to backwards-compatibility it was always clear that type hints would always be optional. However, it’s maybe less obvious that you would be able to use type checkers with code bases where only parts of it use type hints. This was an important aspect of their design. Since type hints arrived very late to Python5, many huge code bases were created prior to their introduction. It would be an impossible feat to add type hints to such large projects if you had to do it all at once.
Therefore, incremental typing is at the core of every type checkers design. This means that you can slowly start adding type hints in some places – preferably your most used and central functions. Step by step, you and your team can expand the amount of typed code, whenever you have time for such a task. Once you are all comfortable using them, you can start enforcing type hints on new code only.
Even if only parts of your code use types, the type checker will still work, and it will check all that it can. Whereever you do not specify a type hint, it implicitely uses the Any type. Any is special, it basically disables type checking for objects of that type. Incremental Typing ensures that introducing type hints to a code base is very approachable.
When starting new projects, I do usually enforce type hints right away though, so that large amounts of untyped code never start to pile up in the first place. Of course, you don’t always have the luxury of working on brand-new projects. But with incremental typing, you can always start somewhere.
🐦 Phew, you really said
typea lot today!
Wrapping Up
While I hope this has inspired some of you to use type hints, I have been intentionally vague on details and only used few examples. This post only serves to instill a need for typing in you. I plan to release another blog post soon that focuses deeply on actual tips, tricks and examples.
🐦 Follow us on Mastodon and subscribe to the RSS feed to not miss it!
But, if you get a chance, I encourage you to just try it out yourself! As mentioned, you can start small and gather some experience before setting more ambitious goals. The benefits will speak for themselves and hopefully encourage you to learn more.
Unless your DataFrame - for whatever reason - has a row with an index “result_column” 🥴
Mostly, because it actually evaluates all your type hints and stores them within the function object. There’s many tools that access these stored type hints and do all sorts of cool stuff with them, see for example pydantic for data validation, typer for building CLI apps, or runtime type checkers like beartype.
There are actually programs that can compile Python code to machine code, like mypyc, Numba or Nuitka. I assume in most cases you will use an interpreter to run your code though.
It actually returns a TextFileReader when you pass it a chunksize parameter, but we will discuss advanced topics like Unions and multiple-dispatch another time.
Python 3.6, the first version to include non-comment type strings, was released on 2016-12-23, at which point - according to Wikipedia - Python was around 25 years old (counting from its first public release v0.9.0).
Comments
You can respond to this post with an account on the Fediverse (e.g Mastodon, Akkoma, Sharkey).
Please be kind to everyone. Critique is welcome, but intolerant or hateful comments will be removed and the author blocked.
Load comments…